CDI-PIO Status-Update 2013-09-24¶
Model integration status¶
ECHAM6 has been ported to allow for everything mo_output currently does via task 0-I/O to be done with I/O servers.
The output mode is controlled by a new parameter nprocio (namelist parctl). Setting nprocio=0 activates conventional task 0 I/O.
I/O servers can be used with ECHAM6 running in standalone and coupled mode (MPI-ESM).
- one copy can be avoided through an API that allows for scattered variables (the associated "holes" are part of how ECHAM does the nproma reshape of variables)
- to improve RMA performance on blizzard some intermediate calls to MPI_Win_test might help, this needs further evaluation
The development branch for ECHAM6 with parallel output using CDI-PIO is
https://svn.mpimet.mpg.de/svn/echam6/branches/echam-cdi-pio-dkrzThe branch is based on trunk/echam-dev. Modifications made in trunk/echam-dev are periodically merged in (currently up to r3444).
Performance status¶
The ECHAM6 port from above has been tested in the following setups:
On blizzard.dkrz.de runs with CDI-PIO do not improve run-time because of two not yet fully understood problemsthe RMA implementation currently spawns an additional thread in case RMA cannot be handled by shared memory alone. The thread enters a busy wait and severely impacts performance of the model integration.Also there is a not-yet-understood variation in the time needed for one I/O timestep that points at some unforeseen problem. This will be investigated furhter by IBM support once the problem can be broken down into a manageable chunk.
- On blizzard.dkrz.de CDI-PIO currently improves run-time
- this so far requires setting environment variable
MP_CSS_INTERRUPT=noand settingMP_IOAGENT_CNT=allor (even better) to only those ranks which host CDI-PIO servers.
- this so far requires setting environment variable
- On thunder
- with OpenMPI integration time decreases but a slight slowdown of all integration steps may occur. Nevertheless, the overall performance gain from reduced output times is noticeable.
- with MVAPICH2 integration time actually decreases. For ECHAM6 T127L95 the gain is by approx. 600 seconds which is fully mirrored in the reduction of time for I/O.
Setting of the environment variableMV2_DEFAULT_PUT_GET_LIST_SIZE=600is required. The value should be increased with the increasing number of processes used.But mvapich2 gives incorrect results for jobs running on 14 or more nodes. This is currently under investigation and after it has been possible to reproducethe problem with a simple test program that works on blizzard but fails in the same way as ECHAM6+CDI-PIO is assumed to be a bug in mvapich2 or the thunderInfiniband hard-or software. The CIS ticket isCIS #67652.
In conclusion, the significant performance benefits achievable on thunder with MVAPICH2 suggest the chosen design is workable. but difficult to exploit on given hardware
Comparison of ECHAM6 T127L95 integration times on cluster Thunder using OpenMPI-1.6.5 and MVAPICH2-1.9b is shown in the Figure below.
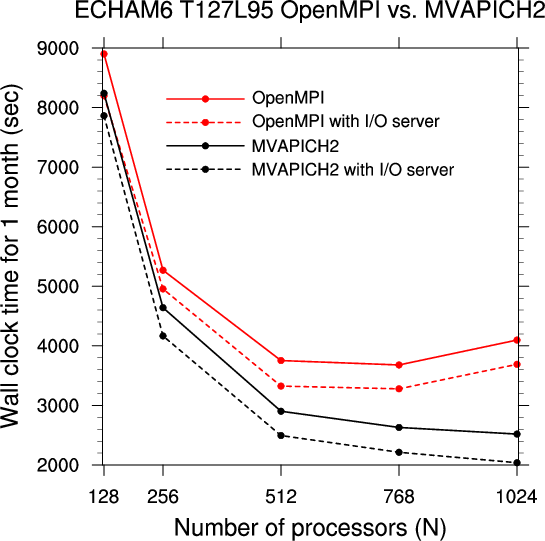
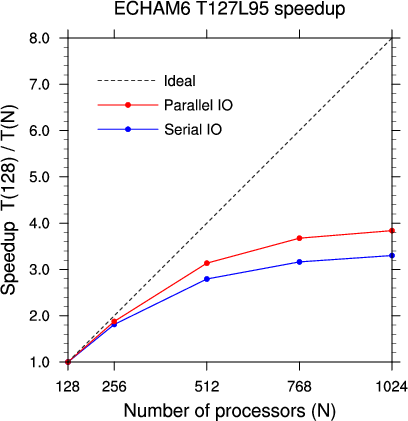
Plots below demonstrate performance gain for ECHAM6 T127L95 with parallel 6-hourly output in comparison to serial output on cluster Thunder.
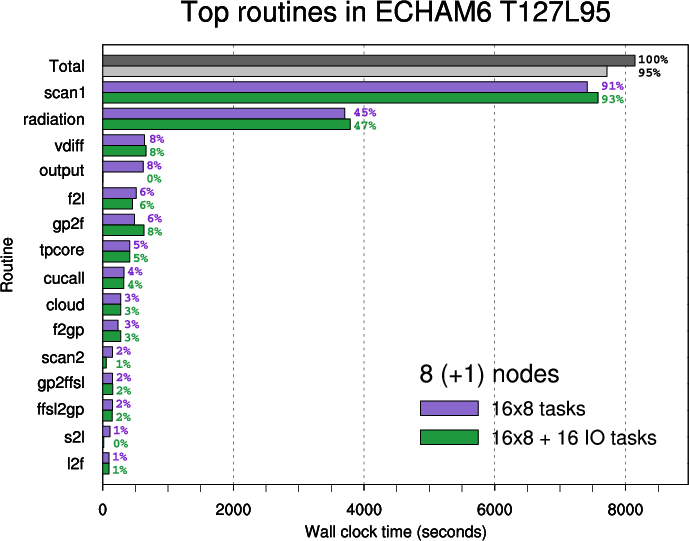
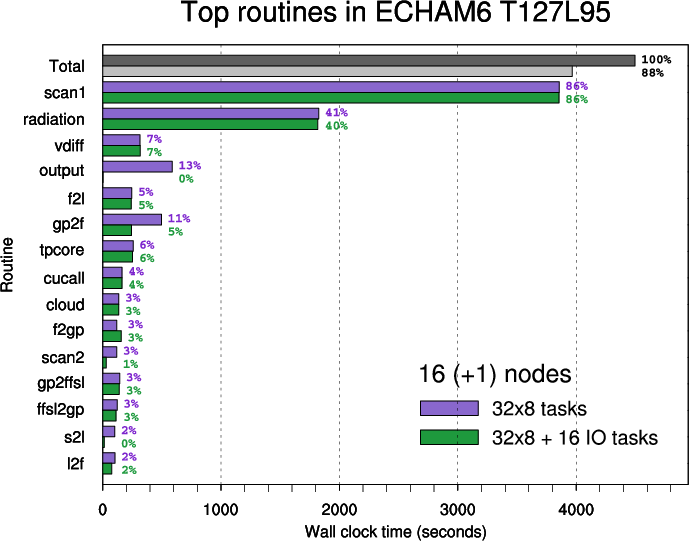
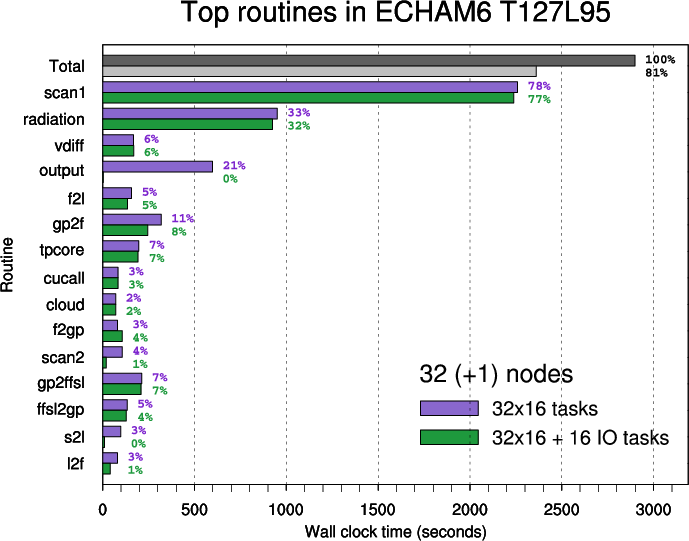
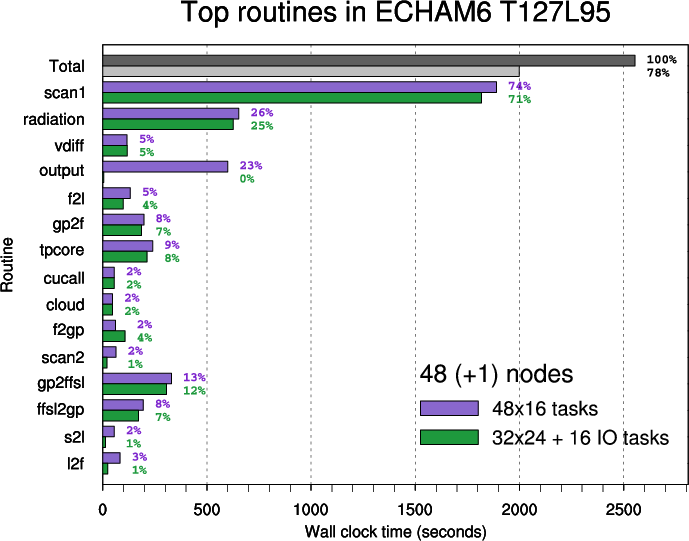
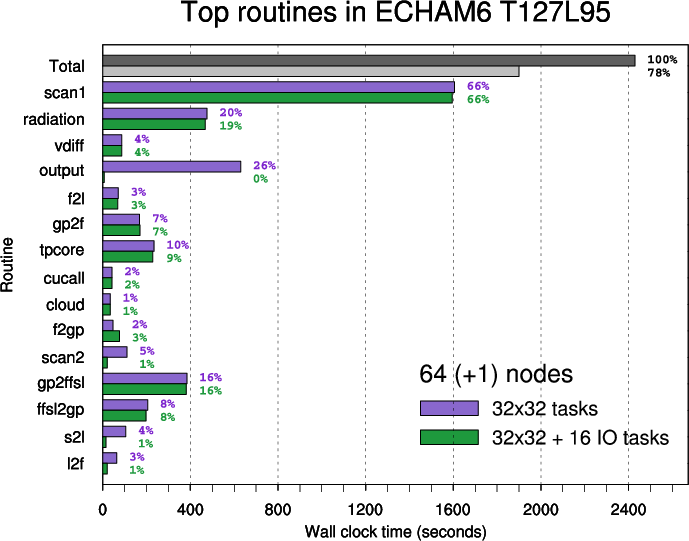
The ranking of the top routines is based on time measurements for 8 nodes. The importance of routines changes with the rising number of nodes
(the relative time spent in transposition routines increases).
- Figure 1: Speedup curves for ECHAM6 T127L95 with parallel and
serial 6h-output compared to run time on 8 nodes (128 tasks)
- Figure 2: Top routines in ECHAM6 T127L95 executed on 8 nodes.
Note: inclusive times are shown (i.e. time spent in child or external routines is not subtracted).
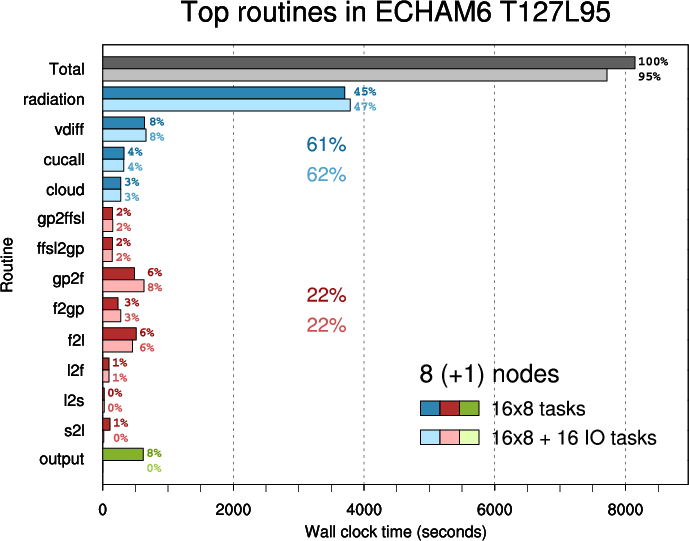
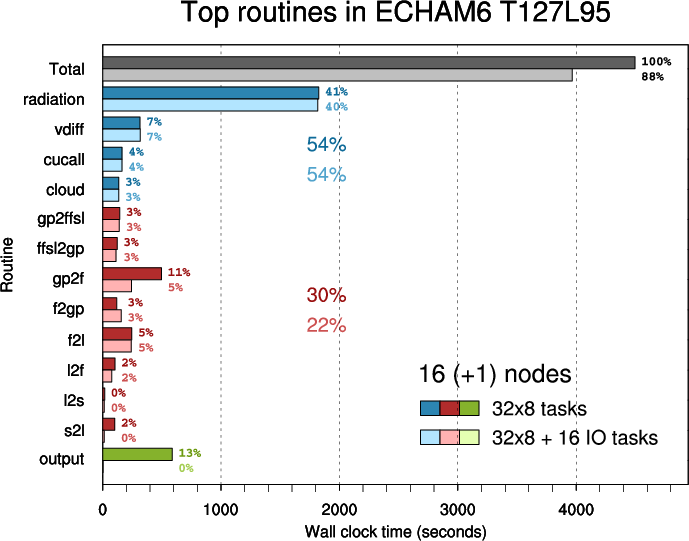
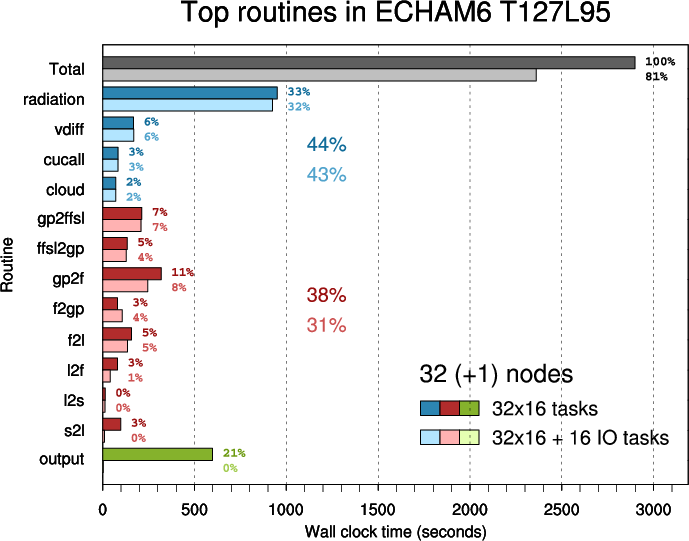
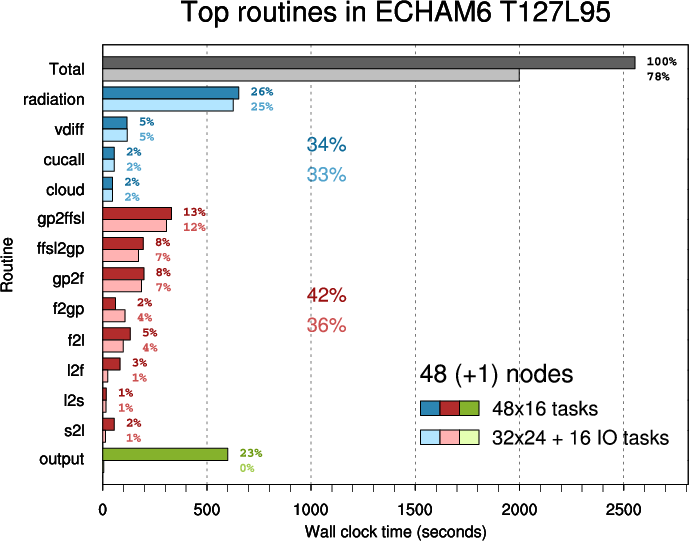
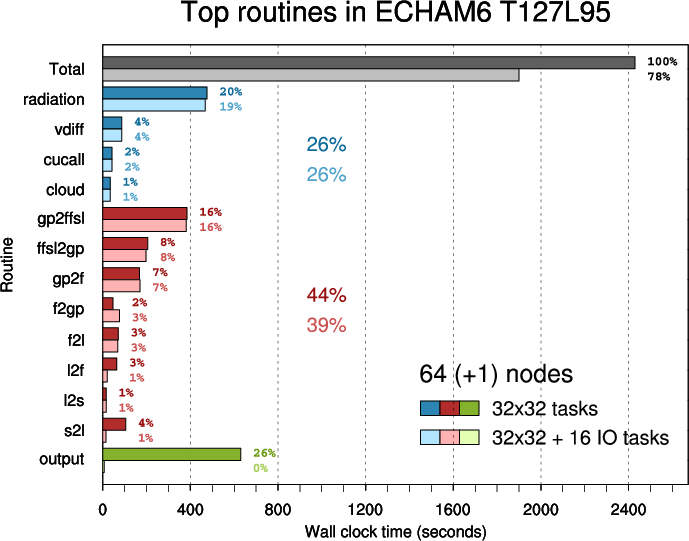
In the second plot parent routines ("scan1", "tpcore", "scan2") are omitted and other routines are arranged in three groups:
Routine "scan1" calls "radiation", "vdiff", "cucall", "cloud", "l2f", "f2gp", "gp2ffsl", "tpcore", "gp2f", "f2l", "l2s".
Routine "tpcore" calls "ffsl2gp".
Routine "scan2" calls "s2l"- physics (blue)
- transpositions (red)
- output (green)
- Figure 3: Top routines in ECHAM6 T127L95 executed on 16 nodes
- Figure 4: Top routines in ECHAM6 T127L95 executed on 32 nodes
- Figure 5: Top routines in ECHAM6 T127L95 executed on 48 nodes
- Figure 6: Top routines in ECHAM6 T127L95 executed on 64 nodes
Future plans¶
To address the shortcomings revealed above and already known problems:- an intermediate solution for blizzard and OpenMPI might be calls to MPI_Win_test to make progress on RMA transfers, this needs further evaluation
- a scalable passing of meta-data needs still to be implemented but is unproblematic for the relatively small amounts of metadata in ECHAM
- an alternative mapping of model tasks to I/O server tasks would probably alleviate the problems witnessed on both blizzard and with thunder/OpenMPI-IB.
- to achieve more throughput for GRIB files than currently available with the already implemented output schemes one needs to develop a method that fully caters to collective MPI I/O routines
- to provide better performance on platforms that have weak RMA implementations it might be prudent to add an alternative means of data transfer via MPI_Send/Recv
- having thought about the problems we have, the following would improve the perfromance even for very large cpu setups: to reduce the one-sided resource pressure we could attach an intermediate storage layer between the I/O servers and the compute CPUs in a way that a bunch (64, 128, 256, or ...) have one intermediate partner for the MPI_get and we can minimize the background resources for the one-sided setup. As well this would disentangle the first step of communication. Between this concentration layer and the I/O servers the communication model can be switched to 'more reliable' MPI communication.
- build a second data flow in single precision as netcdf is written normally in float and for grib packing float is good up to 24bit representation.